FastCGI
在讨论 FastCGI 之前,不得不说传统的 CGI 的工作原理,同时应该大概了解 CGI 1.1 协议
CGI 简介
CGI全称是“通用网关接口”(Common Gateway Interface),它可以让一个客户端,从网页浏览器向执行在Web服务器上的程序请求数据。 CGI描述了客户端和这个程序之间传输数据的一种标准。 CGI的一个目的是要独立于任何语言的,所以CGI可以用任何一种语言编写,只要这种语言具有标准输入、输出和环境变量。 如php,perl,tcl等。
CGI 的运行原理
- 客户端访问某个 URL 地址之后,通过 GET/POST/PUT 等方式提交数据,并通过 HTTP 协议向 Web 服务器发出请求。
- 服务器端的 HTTP Daemon(守护进程)启动一个子进程。然后在子进程中,将 HTTP 请求里描述的信息通过标准输入 stdin 和环境变量传递给 URL 指定的 CGI 程序,并启动此应用程序进行处理,处理结果通过标准输出 stdout 返回给 HTTP Daemon 子进程。
- 再由 HTTP Daemon 子进程通过 HTTP 协议返回给客户端。
上面的这段话理解可能还是比较抽象,下面我们就通过一次 GET 请求为例进行详细说明。
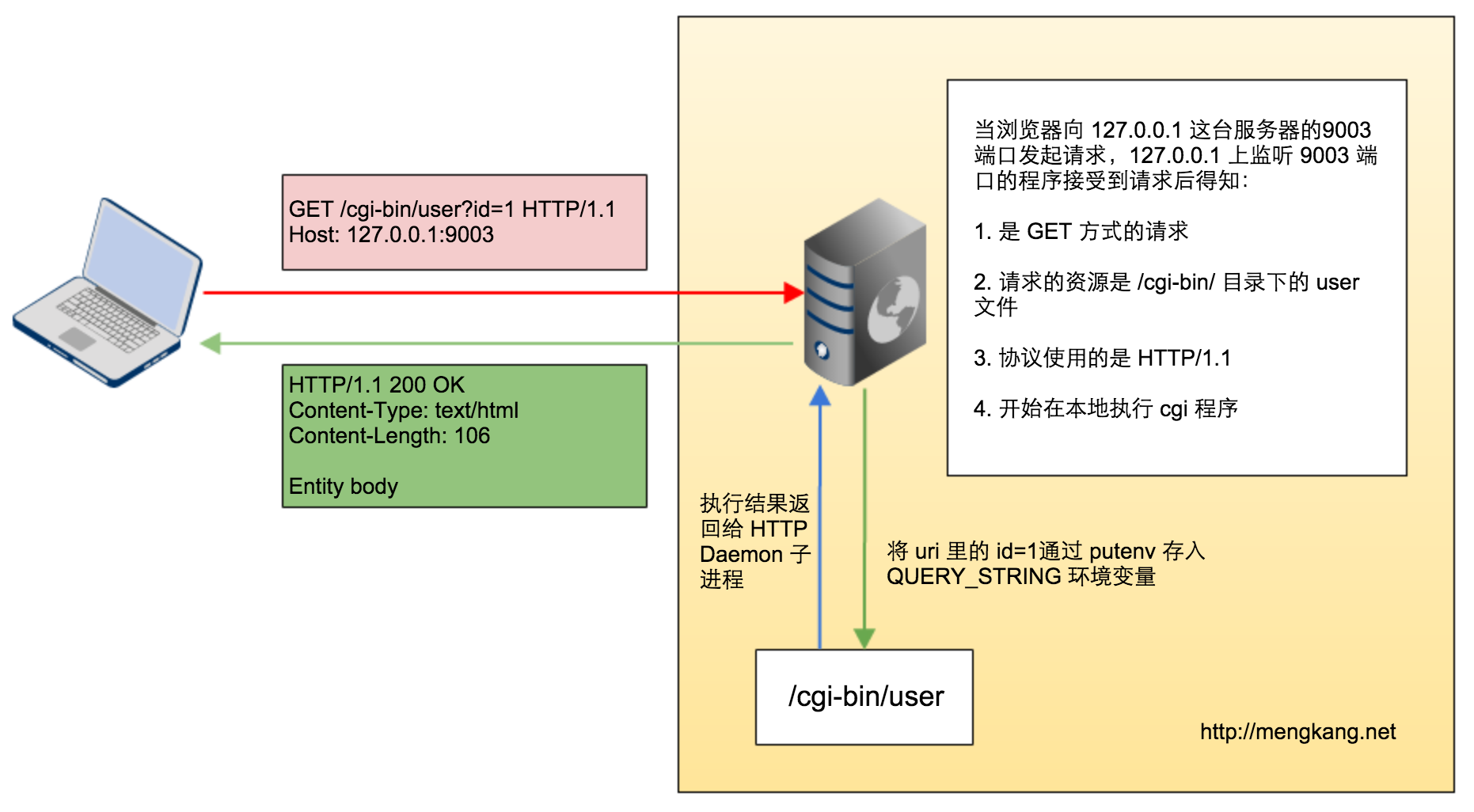
如图所示,本次请求的流程如下:
- 客户端访问 http://127.0.0.1:9003/cgi-bin/user?id=1
- 127.0.0.1 上监听 9003 端口的守护进程接受到该请求
- 通过解析 HTTP 头信息,得知是 GET 请求,并且请求的是
/cgi-bin/目录下的user文件。 - 将 uri 里的
id=1通过存入QUERY_STRING环境变量。 - Web 守护进程 fork 一个子进程,然后在子进程中执行 user 程序,通过环境变量获取到
id。 - 执行完毕之后,将结果通过标准输出返回到子进程。
- 子进程将结果返回给客户端。
下面是演示代码:
Web 服务器程序
[c]
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <string.h>
#define SERV_PORT 9003
char *str_join(char *str1, char *str2);
char *html_response(char *res, char *buf);
int main(void) {
int lfd, cfd;
struct sockaddr_in serv_addr, clin_addr;
socklen_t clin_len;
char buf[1024], web_result[1024];
int len;
FILE *cin;
if ((lfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
perror("create socket failed");
exit(1);
}
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(SERV_PORT);
if (bind(lfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) == -1) {
perror("bind error");
exit(1);
}
if (listen(lfd, 128) == -1) {
perror("listen error");
exit(1);
}
signal(SIGCLD, SIG_IGN);
while (1) {
clin_len = sizeof(clin_addr);
if ((cfd = accept(lfd, (struct sockaddr *) &clin_addr, &clin_len)) == -1) {
perror("接收错误\n");
continue;
}
cin = fdopen(cfd, "r");
setbuf(cin, (char *) 0);
fgets(buf, 1024, cin); //读取第一行
printf("\n%s", buf);
//============================ cgi 环境变量设置演示 ============================
// 例如 "GET /cgi-bin/user?id=1 HTTP/1.1";
char *delim = " ";
char *p;
char *method, *filename, *query_string;
char *query_string_pre = "QUERY_STRING=";
method = strtok(buf, delim); // GET
p = strtok(NULL, delim); // /cgi-bin/user?id=1
filename = strtok(p, "?"); // /cgi-bin/user
if (strcmp(filename, "/favicon.ico") == 0) {
continue;
}
query_string = strtok(NULL, "?"); // id=1
putenv(str_join(query_string_pre, query_string));
//============================ cgi 环境变量设置演示 ============================
int pid = fork();
if (pid > 0) {
close(cfd);
}
else if (pid == 0) {
close(lfd);
FILE *stream = popen(str_join(".", filename), "r");
fread(buf, sizeof(char), sizeof(buf), stream);
html_response(web_result, buf);
write(cfd, web_result, sizeof(web_result));
pclose(stream);
close(cfd);
exit(0);
}
else {
perror("fork error");
exit(1);
}
}
close(lfd);
return 0;
}
char *str_join(char *str1, char *str2) {
char *result = malloc(strlen(str1) + strlen(str2) + 1);
if (result == NULL) exit(1);
strcpy(result, str1);
strcat(result, str2);
return result;
}
char *html_response(char *res, char *buf) {
char *html_response_template = "HTTP/1.1 200 OK\r\nContent-Type:text/html\r\nContent-Length: %d\r\nServer: mengkang\r\n\r\n%s";
sprintf(res, html_response_template, strlen(buf), buf);
return res;
}
如上代码中的重点:
66~81行找到CGI程序的相对路径(我们为了简单,直接将其根目录定义为Web程序的当前目录),这样就可以在子进程中执行 CGI 程序了;同时设置环境变量,方便CGI程序运行时读取; 94~95行将 CGI 程序的标准输出结果写入 Web 服务器守护进程的缓存中; 97行则将包装后的 html 结果写入客户端 socket 描述符,返回给连接Web服务器的客户端。
CGI 程序(user.c)
[c]
#include <stdio.h>
#include <stdlib.h>
// 通过获取的 id 查询用户的信息
int main(void) {
//============================ 模拟数据库 ============================
typedef struct {
int id;
char *username;
int age;
} user;
user users[] = {
{},
{
1,
"mengkang.zhou",
18
}
};
//============================ 模拟数据库 ============================
char *query_string;
int id;
query_string = getenv("QUERY_STRING");
if (query_string == NULL) {
printf("没有输入数据");
} else if (sscanf(query_string, "id=%d", &id) != 1) {
printf("没有输入id");
} else {
printf("用户信息查询<br>学号: %d<br>姓名: %s<br>年龄: %d", id, users[id].username, users[id].age);
}
return 0;
}
将上面的 CGI 程序编译成gcc user.c -o user,放在上面web程序的 ./cgi-bin/ 目录下。
代码中的第28行,从环境变量中读取前面在Web服务器守护进程中设置的环境变量,是我们演示的重点。
FastCGI 简介
FastCGI是Web服务器和处理程序之间通信的一种协议, 是CGI的一种改进方案,FastCGI像是一个常驻(long-lived)型的CGI, 它可以一直执行,在请求到达时不会花费时间去fork一个进程来处理(这是CGI最为人诟病的fork-and-execute模式)。 正是因为他只是一个通信协议,它还支持分布式的运算,所以 FastCGI 程序可以在网站服务器以外的主机上执行,并且可以接受来自其它网站服务器的请求。
FastCGI 是与语言无关的、可伸缩架构的 CGI 开放扩展,将 CGI 解释器进程保持在内存中,以此获得较高的性能。 CGI 程序反复加载是 CGI 性能低下的主要原因,如果 CGI 程序保持在内存中并接受 FastCGI 进程管理器调度, 则可以提供良好的性能、伸缩性、Fail-Over 特性等。
FastCGI 工作流程如下:
- FastCGI 进程管理器自身初始化,启动多个 CGI 解释器进程,并等待来自 Web Server 的连接。
- Web 服务器与 FastCGI 进程管理器进行 Socket 通信,通过 FastCGI 协议发送 CGI 环境变量和标准输入数据给 CGI 解释器进程。
- CGI 解释器进程完成处理后将标准输出和错误信息从同一连接返回 Web Server。
- CGI 解释器进程接着等待并处理来自 Web Server 的下一个连接。
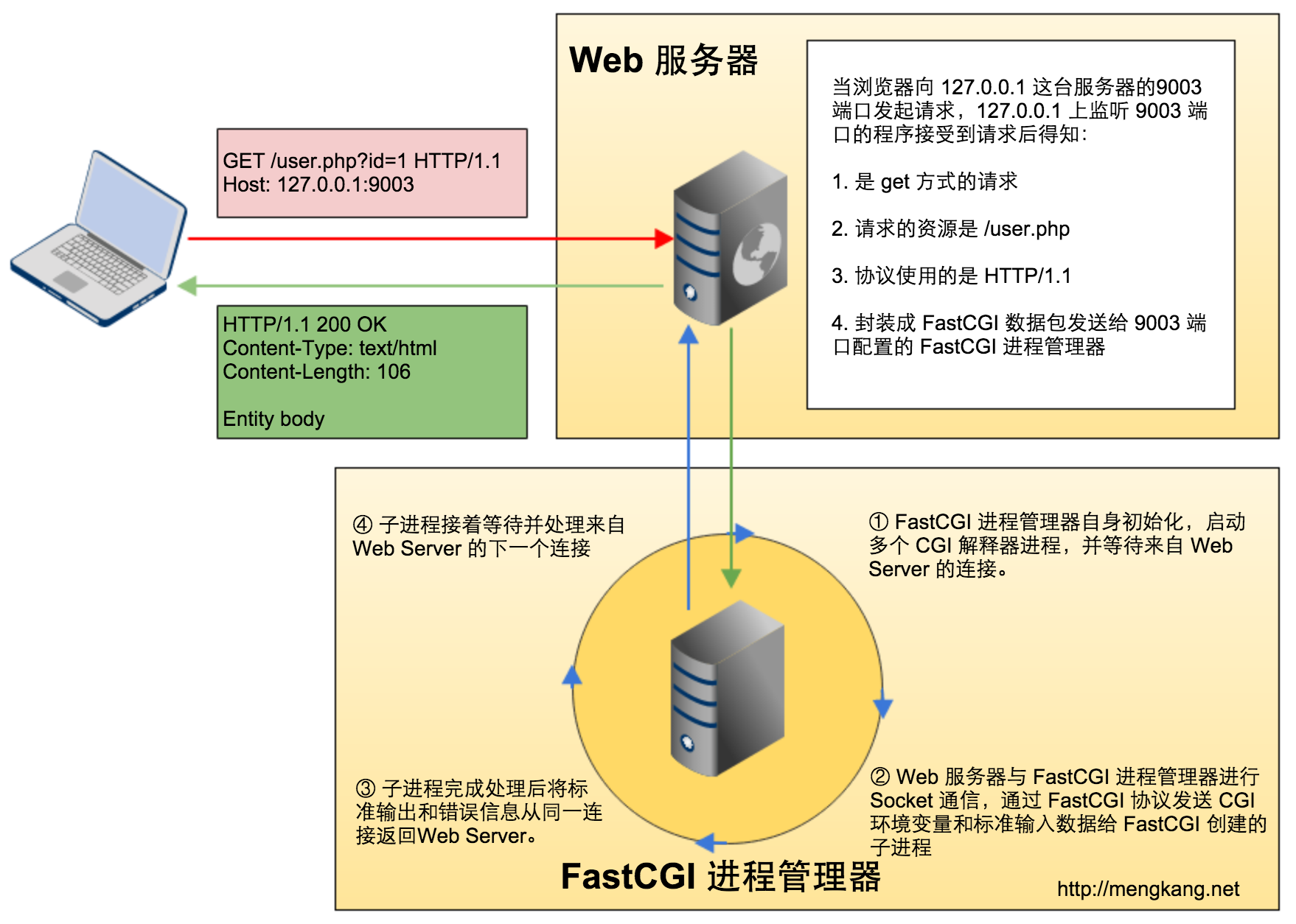
FastCGI 与传统 CGI 模式的区别之一则是 Web 服务器不是直接执行 CGI 程序了,而是通过 Socket 与 FastCGI 响应器(FastCGI 进程管理器)进行交互,也正是由于 FastCGI 进程管理器是基于 Socket 通信的,所以也是分布式的,Web 服务器可以和 CGI 响应器服务器分开部署。Web 服务器需要将数据 CGI/1.1 的规范封装在遵循 FastCGI 协议包中发送给 FastCGI 响应器程序。
FastCGI 协议
可能上面的内容理解起来还是很抽象,这是由于第一对FastCGI协议还没有一个大概的认识,第二没有实际代码的学习。所以需要预先学习下 FastCGI 协议,不一定需要完全看懂,可大致了解之后,看完本篇再结合着学习理解消化。
下面结合 PHP 的 FastCGI 的代码进行分析,不作特殊说明以下代码均来自于 PHP 源码。
FastCGI 消息类型
FastCGI 将传输的消息做了很多类型的划分,其结构体定义如下:
[c]
typedef enum _fcgi_request_type {
FCGI_BEGIN_REQUEST = 1, /* [in] */
FCGI_ABORT_REQUEST = 2, /* [in] (not supported) */
FCGI_END_REQUEST = 3, /* [out] */
FCGI_PARAMS = 4, /* [in] environment variables */
FCGI_STDIN = 5, /* [in] post data */
FCGI_STDOUT = 6, /* [out] response */
FCGI_STDERR = 7, /* [out] errors */
FCGI_DATA = 8, /* [in] filter data (not supported) */
FCGI_GET_VALUES = 9, /* [in] */
FCGI_GET_VALUES_RESULT = 10 /* [out] */
} fcgi_request_type;
消息的发送顺序
下图是一个比较常见消息传递流程
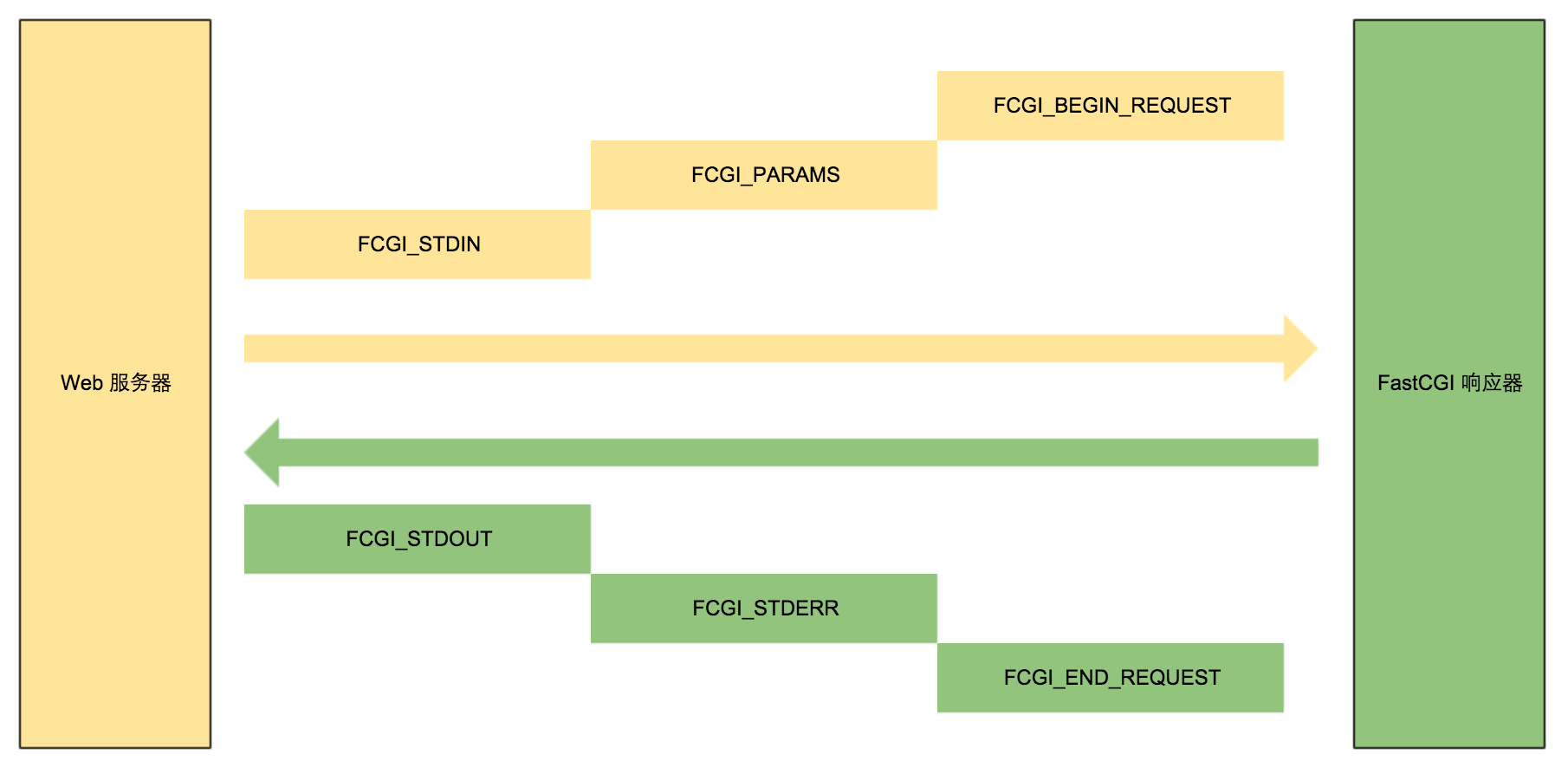
最先发送的是FCGI_BEGIN_REQUEST,然后是FCGI_PARAMS和FCGI_STDIN,由于每个消息头(下面将详细说明)里面能够承载的最大长度是65535,所以这两种类型的消息不一定只发送一次,有可能连续发送多次。
FastCGI 响应体处理完毕之后,将发送FCGI_STDOUT、FCGI_STDERR,同理也可能多次连续发送。最后以FCGI_END_REQUEST表示请求的结束。
需要注意的一点,FCGI_BEGIN_REQUEST和FCGI_END_REQUEST分别标识着请求的开始和结束,与整个协议息息相关,所以他们的消息体的内容也是协议的一部分,因此也会有相应的结构体与之对应(后面会详细说明)。而环境变量、标准输入、标准输出、错误输出,这些都是业务相关,与协议无关,所以他们的消息体的内容则无结构体对应。
由于整个消息是二进制连续传递的,所以必须定义一个统一的结构的消息头,这样以便读取每个消息的消息体,方便消息的切割。这在网络通讯中是非常常见的一种手段。
FastCGI 消息头
如上,FastCGI 消息分10种消息类型,有的是输入有的是输出。而所有的消息都以一个消息头开始。其结构体定义如下:
[c]
typedef struct _fcgi_header {
unsigned char version;
unsigned char type;
unsigned char requestIdB1;
unsigned char requestIdB0;
unsigned char contentLengthB1;
unsigned char contentLengthB0;
unsigned char paddingLength;
unsigned char reserved;
} fcgi_header;
字段解释下:
version标识FastCGI协议版本。
type 标识FastCGI记录类型,也就是记录执行的一般职能。
requestId标识记录所属的FastCGI请求。
contentLength记录的contentData组件的字节数。
关于上面的xxB1和xxB0的协议说明:当两个相邻的结构组件除了后缀“B1”和“B0”之外命名相同时,它表示这两个组件可视为估值为B1<<8 + B0的单个数字。该单个数字的名字是这些组件减去后缀的名字。这个约定归纳了一个由超过两个字节表示的数字的处理方式。
比如协议头中requestId和contentLength表示的最大值就是 65535。
[c]
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
int main()
{
unsigned char requestIdB1 = UCHAR_MAX;
unsigned char requestIdB0 = UCHAR_MAX;
printf("%d\n", (requestIdB1 << 8) + requestIdB0); // 65535
}
你可能会想到如果一个消息体长度超过65535怎么办,则分割为多个相同类型的消息发送即可。
FCGI_BEGIN_REQUEST 的定义
[c]
typedef struct _fcgi_begin_request {
unsigned char roleB1;
unsigned char roleB0;
unsigned char flags;
unsigned char reserved[5];
} fcgi_begin_request;
字段解释:
role表示Web服务器期望应用扮演的角色。分为三个角色(而我们这里讨论的情况一般都是响应器角色)
[c]
typedef enum _fcgi_role {
FCGI_RESPONDER = 1,
FCGI_AUTHORIZER = 2,
FCGI_FILTER = 3
} fcgi_role;
而FCGI_BEGIN_REQUEST中的flags组件包含一个控制线路关闭的位:flags & FCGI_KEEP_CONN:如果为0,则应用在对本次请求响应后关闭线路。如果非0,应用在对本次请求响应后不会关闭线路;Web服务器为线路保持响应性。
FCGI_END_REQUEST 的定义
[c]
typedef struct _fcgi_end_request {
unsigned char appStatusB3;
unsigned char appStatusB2;
unsigned char appStatusB1;
unsigned char appStatusB0;
unsigned char protocolStatus;
unsigned char reserved[3];
} fcgi_end_request;
字段解释:
appStatus组件是应用级别的状态码。
protocolStatus组件是协议级别的状态码;protocolStatus的值可能是:
FCGI_REQUEST_COMPLETE:请求的正常结束。
FCGI_CANT_MPX_CONN:拒绝新请求。这发生在Web服务器通过一条线路向应用发送并发的请求时,后者被设计为每条线路每次处理一个请求。
FCGI_OVERLOADED:拒绝新请求。这发生在应用用完某些资源时,例如数据库连接。
FCGI_UNKNOWN_ROLE:拒绝新请求。这发生在Web服务器指定了一个应用不能识别的角色时。
protocolStatus在 PHP 中的定义如下
[c]
typedef enum _fcgi_protocol_status {
FCGI_REQUEST_COMPLETE = 0,
FCGI_CANT_MPX_CONN = 1,
FCGI_OVERLOADED = 2,
FCGI_UNKNOWN_ROLE = 3
} dcgi_protocol_status;
需要注意dcgi_protocol_status和fcgi_role各个元素的值都是 FastCGI 协议里定义好的,而非 PHP 自定义的。
消息通讯样例
为了简单的表示,消息头只显示消息的类型和消息的 id,其他字段都不予以显示。而一行表示一个数据包。下面的例子来自于官网
{FCGI_BEGIN_REQUEST, 1, {FCGI_RESPONDER, 0}}
{FCGI_PARAMS, 1, "\013\002SERVER_PORT80\013\016SERVER_ADDR199.170.183.42 ... "}
{FCGI_STDIN, 1, "quantity=100&item=3047936"}
{FCGI_STDOUT, 1, "Content-type: text/html\r\n\r\n<html>\n<head> ... "}
{FCGI_END_REQUEST, 1, {0, FCGI_REQUEST_COMPLETE}}
配合上面各个结构体,则可以大致想到 FastCGI 响应器的解析和响应流程:
首先读取消息头,得到其类型为FCGI_BEGIN_REQUEST,然后解析其消息体,得知其需要的角色就是FCGI_RESPONDER,flag为0,表示请求结束后关闭线路。然后解析第二段消息,得知其消息类型为FCGI_PARAMS,然后直接将消息体里的内容以回车符切割后存入环境变量。与之类似,处理完毕之后,则返回了FCGI_STDOUT消息体和FCGI_END_REQUEST消息体供 Web 服务器解析。
PHP中的CGI实现
PHP的CGI实现了FastCGI协议,是一个TCP或UDP协议的服务器接受来自Web服务器的请求, 当启动时创建TCP/UDP协议的服务器的socket监听,并接收相关请求进行处理。随后就进入了PHP的生命周期: 模块初始化,sapi初始化,处理PHP请求,模块关闭,sapi关闭等就构成了整个CGI的生命周期。
以TCP为例,在TCP的服务端,一般会执行这样几个操作步骤:
- 调用socket函数创建一个TCP用的流式套接字;
- 调用bind函数将服务器的本地地址与前面创建的套接字绑定;
- 调用listen函数将新创建的套接字作为监听,等待客户端发起的连接,当客户端有多个连接连接到这个套接字时,可能需要排队处理;
- 服务器进程调用accept函数进入阻塞状态,直到有客户进程调用connect函数而建立起一个连接;
- 当与客户端创建连接后,服务器调用read_stream函数读取客户的请求;
- 处理完数据后,服务器调用write函数向客户端发送应答。
TCP上客户-服务器事务的时序如图2.6所示:
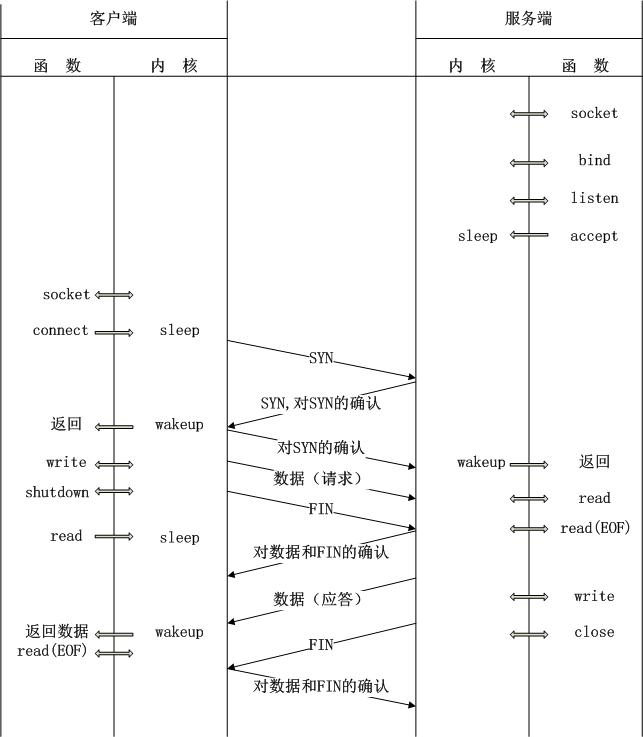
PHP的CGI实现从cgi_main.c文件的main函数开始,在main函数中调用了定义在fastcgi.c文件中的初始化,监听等函数。 对比TCP的流程,我们查看PHP对TCP协议的实现,虽然PHP本身也实现了这些流程,但是在main函数中一些过程被封装成一个函数实现。 对应TCP的操作流程,PHP首先会执行创建socket,绑定套接字,创建监听:
[c]
if (bindpath) {
fcgi_fd = fcgi_listen(bindpath, 128); // 实现socket监听,调用fcgi_init初始化
...
}
在fastcgi.c文件中,fcgi_listen函数主要用于创建、绑定socket并开始监听,它走完了前面所列TCP流程的前三个阶段,
[c]
if ((listen_socket = socket(sa.sa.sa_family, SOCK_STREAM, 0)) < 0 ||
...
bind(listen_socket, (struct sockaddr *) &sa, sock_len) < 0 ||
listen(listen_socket, backlog) < 0) {
...
}
当服务端初始化完成后,进程调用accept函数进入阻塞状态,在main函数中我们看到如下代码:
[c]
while (parent) {
do {
pid = fork(); // 生成新的子进程
switch (pid) {
case 0: // 子进程
parent = 0;
/* don't catch our signals */
sigaction(SIGTERM, &old_term, 0); // 终止信号
sigaction(SIGQUIT, &old_quit, 0); // 终端退出符
sigaction(SIGINT, &old_int, 0); // 终端中断符
break;
...
default:
/* Fine */
running++;
break;
} while (parent && (running < children));
...
while (!fastcgi || fcgi_accept_request(&request) >= 0) {
SG(server_context) = (void *) &request;
init_request_info(TSRMLS_C);
CG(interactive) = 0;
...
}
如上的代码是一个生成子进程,并等待用户请求。在fcgi_accept_request函数中,程序会调用accept函数阻塞新创建的进程。 当用户的请求到达时,fcgi_accept_request函数会判断是否处理用户的请求,其中会过滤某些连接请求,忽略受限制客户的请求, 如果程序受理用户的请求,它将分析请求的信息,将相关的变量写到对应的变量中。 其中在读取请求内容时调用了safe_read方法。如下所示: [main() -> fcgi_accept_request() -> fcgi_read_request() -> safe_read()]
[c]
static inline ssize_t safe_read(fcgi_request *req, const void *buf, size_t count)
{
size_t n = 0;
do {
... // 省略 对win32的处理
ret = read(req->fd, ((char*)buf)+n, count-n); // 非win版本的读操作
... // 省略
} while (n != count);
}
如上对应服务器端读取用户的请求数据。
在请求初始化完成,读取请求完毕后,就该处理请求的PHP文件了。 假设此次请求为PHP_MODE_STANDARD则会调用php_execute_script执行PHP文件。 在此函数中它先初始化此文件相关的一些内容,然后再调用zend_execute_scripts函数,对PHP文件进行词法分析和语法分析,生成中间代码, 并执行zend_execute函数,从而执行这些中间代码。关于整个脚本的执行请参见第三节 脚本的执行。
在处理完用户的请求后,服务器端将返回信息给客户端,此时在main函数中调用的是fcgi_finish_request(&request, 1); fcgi_finish_request函数定义在fastcgi.c文件中,其代码如下:
[c]
int fcgi_finish_request(fcgi_request *req, int force_close)
{
int ret = 1;
if (req->fd >= 0) {
if (!req->closed) {
ret = fcgi_flush(req, 1);
req->closed = 1;
}
fcgi_close(req, force_close, 1);
}
return ret;
}
如上,当socket处于打开状态,并且请求未关闭,则会将执行后的结果刷到客户端,并将请求的关闭设置为真。 将数据刷到客户端的程序调用的是fcgi_flush函数。在此函数中,关键是在于答应头的构造和写操作。 程序的写操作是调用的safe_write函数,而safe_write函数中对于最终的写操作针对win和linux环境做了区分, 在Win32下,如果是TCP连接则用send函数,如果是非TCP则和非win环境一样使用write函数。如下代码:
[c]
#ifdef _WIN32
if (!req->tcp) {
ret = write(req->fd, ((char*)buf)+n, count-n);
} else {
ret = send(req->fd, ((char*)buf)+n, count-n, 0);
if (ret <= 0) {
errno = WSAGetLastError();
}
}
#else
ret = write(req->fd, ((char*)buf)+n, count-n);
#endif
在发送了请求的应答后,服务器端将会执行关闭操作,仅限于CGI本身的关闭,程序执行的是fcgi_close函数。 fcgi_close函数在前面提的fcgi_finish_request函数中,在请求应答完后执行。同样,对于win平台和非win平台有不同的处理。 其中对于非win平台调用的是write函数。
以上是一个TCP服务器端实现的简单说明。这只是我们PHP的CGI模式的基础,在这个基础上PHP增加了更多的功能。 在前面的章节中我们提到了每个SAPI都有一个专属于它们自己的sapi_module_struct结构:cgi_sapi_module,其代码定义如下:
[c]
/* {{{ sapi_module_struct cgi_sapi_module
*/
static sapi_module_struct cgi_sapi_module = {
"cgi-fcgi", /* name */
"CGI/FastCGI", /* pretty name */
php_cgi_startup, /* startup */
php_module_shutdown_wrapper, /* shutdown */
sapi_cgi_activate, /* activate */
sapi_cgi_deactivate, /* deactivate */
sapi_cgibin_ub_write, /* unbuffered write */
sapi_cgibin_flush, /* flush */
NULL, /* get uid */
sapi_cgibin_getenv, /* getenv */
php_error, /* error handler */
NULL, /* header handler */
sapi_cgi_send_headers, /* send headers handler */
NULL, /* send header handler */
sapi_cgi_read_post, /* read POST data */
sapi_cgi_read_cookies, /* read Cookies */
sapi_cgi_register_variables, /* register server variables */
sapi_cgi_log_message, /* Log message */
NULL, /* Get request time */
NULL, /* Child terminate */
STANDARD_SAPI_MODULE_PROPERTIES
};
/* }}} */
同样,以读取cookie为例,当我们在CGI环境下,在PHP中调用读取Cookie时, 最终获取的数据的位置是在激活SAPI时。它所调用的方法是read_cookies。 由SAPI实现来实现获取cookie,这样各个不同的SAPI就能根据自己的需要来实现一些依赖环境的方法。
[c]
SG(request_info).cookie_data = sapi_module.read_cookies(TSRMLS_C);
所有使用PHP的场合都需要定义自己的SAPI,例如在第一小节的Apache模块方式中, sapi_module是apache2_sapi_module,其对应read_cookies方法的是php_apache_sapi_read_cookies函数, 而在我们这里,读取cookie的函数是sapi_cgi_read_cookies。 从sapi_module结构可以看出flush对应的是sapi_cli_flush,在win或非win下,flush对应的操作不同, 在win下,如果输出缓存失败,则会和嵌入式的处理一样,调用php_handle_aborted_connection进入中断处理程序, 而其它情况则是没有任何处理程序。这个区别通过cli_win.c中的PHP_CLI_WIN32_NO_CONSOLE控制。